
Künstliche Intelligenz (KI) gilt heute als Schlüsseltechnologie der Automatisierung. Sie imitiert menschliche Lern- und Entscheidungsprozesse und erschließt neue Wege zur Prozessoptimierung, Qualitätssteigerung und Energieeffizienz. Der erfolgreichste Ansatz ist das Maschinelle Lernen (ML) – das Erkennen von Mustern und Zusammenhängen aus Beispieldaten.
Beckhoff integriert diese Technologie konsequent in die PC-based-Control-Welt: Mit TwinCAT 3 Machine Learning wird KI zu einem integralen Bestandteil der Maschinensteuerung.
Das Ergebnis: ein offenes, durchgängiges Ökosystem aus Hardware und Software, das KI-Modelle direkt auf der SPS lauffähig macht – ohne externe Systeme oder Spezialwissen.
Erfahren Sie, wie Beckhoff die Brücke zwischen Datenaufnahme, Training und Echtzeit-Inferenz schlägt – und wie Sie mit TwinCAT 3 Machine Learning KI direkt in Ihre Steuerung integrieren können.
KI-Anwendungen in der industriellen Automation – neue Potenziale erkennen
Künstliche Intelligenz eröffnet im Maschinen- und Anlagenbau neue Wege, um Qualität, Produktivität und Effizienz zu steigern. Sie ergänzt klassische Regelungs- und Automatisierungskonzepte überall dort, wo herkömmliche Algorithmen an Grenzen stoßen, etwa bei hoher Varianz, komplexen Datenmustern oder schwer modellierbaren Prozessen.
KI-Systeme lernen aus Beispielen, erkennen Zusammenhänge selbstständig und treffen datenbasierte Entscheidungen. Dadurch werden Maschinen adaptiver, präziser und vorausschauender.
Computer Vision: Maschinen sehen und verstehen
Die automatisierte visuelle Qualitätskontrolle gehört zu den wichtigsten und zugleich anspruchsvollsten Einsatzbereichen von KI in der Industrie. Während klassische Bildverarbeitungsalgorithmen gut definierte Aufgaben lösen, etwa Längenmessungen oder Kantenprüfungen, entfalten KI-basierte Verfahren ihre Stärke bei natürlicher Varianz und unregelmäßigen Mustern, dort, wo herkömmliche Regeln versagen.
- hohe Robustheit gegenüber Beleuchtungs- und Umgebungsänderungen
- Anpassungsfähigkeit an neue Produktvarianten durch Retraining
- 100 %-Prüfraten ohne manuelle Parameteroptimierung
- nahtlose Integration in Steuerungssysteme mit TwinCAT
- Qualitäts- und Oberflächenprüfung
Erkennung von Rissen, Kratzern, Verschmutzungen oder Formabweichungen auf metallischen, hölzernen oder polymeren Oberflächen
(Beispiel: End-of-Line-Prüfung von Metallkomponenten, Holzpaneelen oder Spritzgussteilen) - Klassifikation und Sortierung
Sortierung natürlicher Produkte nach Qualitätsstufen, Farbe, Reifegrad oder Beschädigung
(Beispiel: Klassifikation von Eiern, Früchten oder anderen landwirtschaftlichen Erzeugnissen) - Anomalieerkennung in Prozessen
visuelle Überwachung von Verpackungs-, Schweiß- oder Montageprozessen zur Erkennung fehlerhafter Abläufe
(Beispiel: Detektion fehlerhafter Siegelnähte bei Lebensmittelverpackungen) - Objekterkennung und Lokalisierung
KI-gestützte Detektion von Bauteilen, Bohrungen oder Markierungen für robotergestützte Pick-and-Place- oder Montageprozesse
(Beispiel: Ausrichtung einer Flasche anhand des PET-Logos für präzises Etikettieren)
Signals and Time Series: Maschinen hören und fühlen
Neben visuellen Daten sind zeitbasierte Signale die Grundlage vieler industrieller KI-Anwendungen. Strom-, Druck-, Vibrations- oder Temperaturverläufe geben Aufschluss über den Zustand von Prozessen, Komponenten und Werkzeugen. KI-Modelle erkennen Muster und Abweichungen frühzeitig – und ermöglichen so Predictive Maintenance, Prozessoptimierung und Anomalieerkennung in Echtzeit.
- Erkennung subtiler Muster jenseits klassischer Schwellenwerte
- Kombination mehrerer Sensorsignale zu holistischen Zustandsmodellen
- nahtlose Integration in Steuerungssysteme mit TwinCAT
- Prozessüberwachung und Qualitätssicherung
KI-basierte Beurteilung von Schweiß-, Press- oder Verpackungsprozessen anhand elektrischer oder mechanischer Signale
(Beispiel: Erkennen fehlerhafter Versiegelungen anhand von Servostromprofilen) - Prozessoptimierung
dynamische Anpassung von Parametern wie Presskraft, Vorschub oder Temperatur für maximale Energieeffizienz und Produktqualität
(Beispiel: Adaptive Vorschubregelung bei Fräsprozessen basierend auf Stromverläufen) - Forecasting und Regelung
kurzfristige Prognosen von Prozessgrößen wie Windrichtung, Druck oder Temperatur zur prädiktiven Regelung
(Beispiel: Vorhersage von Windgeschwindigkeit und Windrichtung zur optimalen Ausrichtung von Windturbinen) - Zustandsüberwachung und Predictive Maintenance
Früherkennung von Lagerschäden, Unwuchten oder Pumpenverschleiß durch Analyse von Vibrations- und Stromsignalen
(Beispiel: Erkennung von Kompressordefekten über Temperatur- und Stromkurven)
Von den Daten zur Anwendung
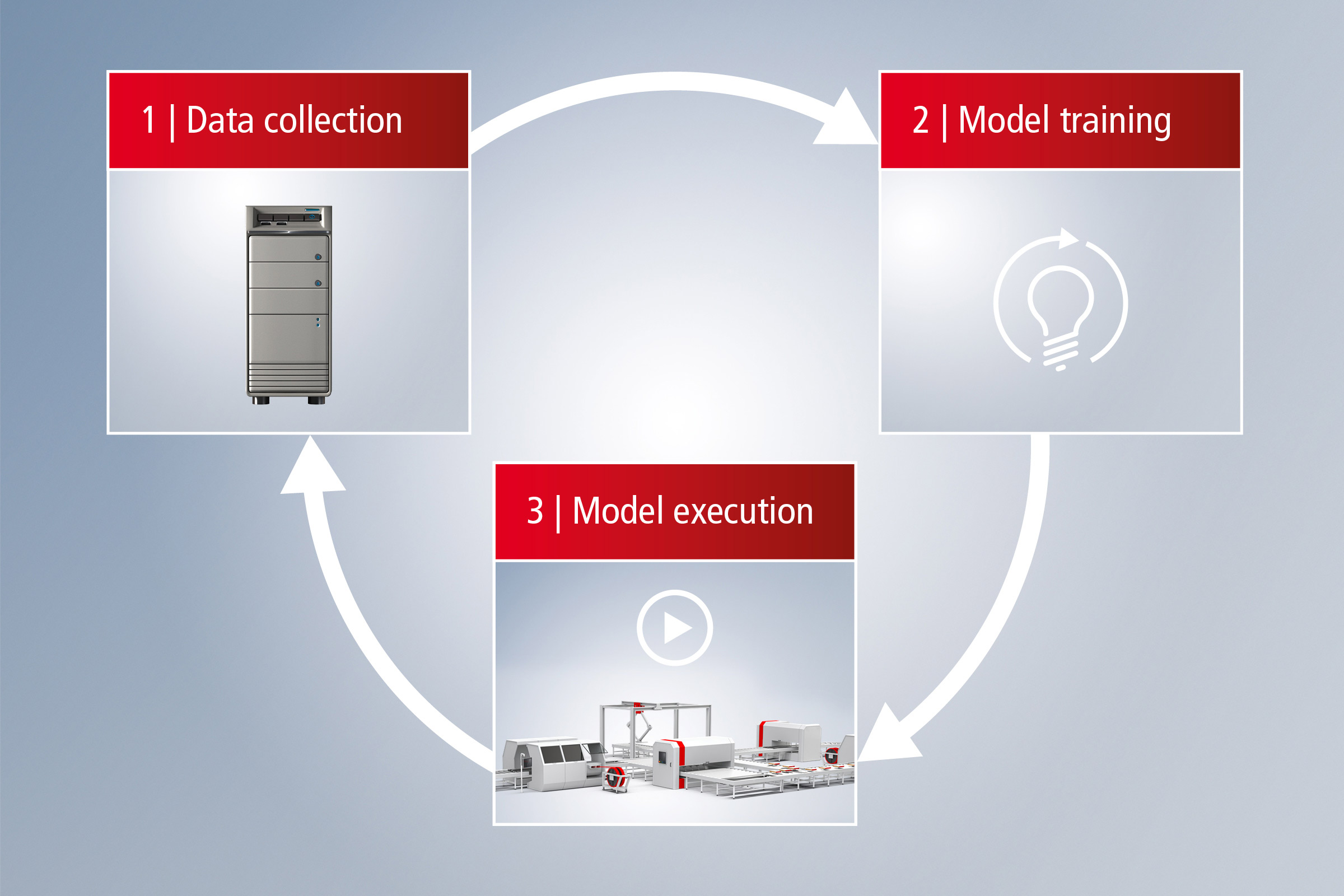
Beckhoff bietet einen durchgängigen Workflow von der Datenerfassung bis zur Echtzeit-Ausführung – vollständig integriert, offen und ohne Lock-in-Effekte. Dank der Systemoffenheit bietet Beckhoff die Möglichkeit, spezifischen Anforderungen mithilfe von Werkzeugen und Funktionen aus dem TwinCAT-Baukasten gerecht zu werden. Das gilt auch für eine bereits vorhandene Systeminfrastruktur, die nicht auf Beckhoff Produkten basiert.
Im Folgenden erfahren Sie mehr zu den Möglichkeiten, die Ihnen Beckhoff entlang des rechts skizzierten Workflows bietet.
Jede Applikation und auch jede IT-Infrastruktur stellt individuelle Ansprüche an die Art zur Beschaffung von Maschinendaten: SQL oder noSQL, Datei-basiert, lokal oder remote, eingeschränkte Port-Freigaben, Cloud-basierter Datalake und viele mehr. Für alle diese Szenarien steht eine Vielzahl etablierter TwinCAT-Produkte zur Verfügung, zum Beispiel TF6420 TwinCAT 3 Database Server, TF3300 TwinCAT 3 Scope Server, TF3500 TwinCAT 3 Analytics Logger oder TF6720 TwinCAT 3 IoT Data Agent. Für Bilddaten steht mit TwinCAT Vision eine ganze Produktfamilie zur Bildaufnahme, Bild(vor)verarbeitung sowie Bildspeicherung zur Verfügung.
Die Grundlage des maschinellen Lernens sind saubere, repräsentative Datensätze. Je nach Aufgabe werden diese vorverarbeitet, gelabelt und anschließend trainiert – automatisiert oder manuell.
Für Automatisierungs- und Prozessexperten
TE3850 TwinCAT 3 Machine Learning Creator bildet die zentrale Plattform, über die Anwender ohne KI-Vorkenntnisse einfach und intuitiv zu eigenen KI-Modellen gelangen. Mit dem Modul TE3851 TwinCAT 3 Machine Learning Creator Computer Vision lassen sich bildbasierte Vision-Anwendungen trainieren, von Qualitätsinspektionen bis zur Objekterkennung. Das Modul TE3852 TwinCAT 3 Machine Learning Creator Signals and Time Series ergänzt die Plattform um leistungsstarke Funktionen für Signal- und Zeitreihenanalysen, etwa für Anomalieerkennung, Predictive Maintenance oder Prozessüberwachung.
- automatisiertes, intuitives Training über eine webbasierte No-Code-Oberfläche
- optimiert auf Genauigkeit und Latenz für Beckhoff Hardware
- Export im offenen ONNX-Format für maximale Interoperabilität
- Bereitstellung eines PLCopen-XML-Files für die direkte Integration in TwinCAT
So entsteht ein standardisierter, reproduzierbarer Trainingsprozess, ganz ohne Data-Science-Know-how.
Für KI-Experten
KI-Experten haben je nach Zielsetzung und Arbeitsweise zwei mögliche Rollen im Beckhoff Ökosystem:
- Der KI-Experte mit dem Machine Learning Creator
Der TwinCAT 3 Machine Learning Creator kann als Effizienzwerkzeug dienen, um den Trainingsprozess zu standardisieren, zu beschleunigen und zu dokumentieren. Data Scientists nutzen das Werkzeug, um schnell ein erstes Modell („Version 0“) zu generieren, Benchmark-Daten zu erstellen oder verschiedene Konfigurationen zu vergleichen. Die erzeugten Modelle können anschließend über ONNX in spezialisierte KI-Frameworks importiert und dort weiter verfeinert werden. - Der KI-Experte als unabhängiger Framework-Nutzer
Alternativ können Data Scientists vollständig in ihrer gewohnten Umgebung arbeiten. Modelle, die in Frameworks wie z. B. PyTorch oder TensorFlow trainiert werden, lassen sich direkt als ONNX-Datei exportieren und in das Beckhoff KI-System integrieren. Damit bleibt die komplette Freiheit in der Modellgestaltung erhalten – während die Ausführung nahtlos in TwinCAT erfolgt.
Beide Ansätze sind vollständig kompatibel und interoperabel. So können Unternehmen ihre vorhandene KI-Kompetenz ohne Lock-in-Effekt, aber mit maximaler Integrationstiefe optimal mit den Echtzeit- und Automatisierungsvorteilen der Beckhoff Welt verbinden.
Liegt das trainierte Modell als ONNX-Datei vor, kann es direkt auf dem Steuerungsrechner geladen und ausgeführt werden. So wird KI zu einem integralen Bestandteil der SPS-Applikation – mit allen Vorteilen:
- keine zusätzliche Hardware oder Schnittstellen notwendig
- einheitliches System für Wartung, Security und Updates
- direkter Zugriff auf alle Maschinendaten in Echtzeit
- kosteneffizient, skalierbar und transparent
Hardware
Je nach Modellgröße und Latenzanforderung stehen verschiedene Hardwareoptionen zur Verfügung, von CPU-basierten bis GPU-beschleunigten Lösungen.
CPU-basierte Ausführung: Für viele Anwendungen genügt die Ausführung der KI-Modelle auf Standard-CPUs ohne zusätzliche Spezialhardware. Das gewohnte Beckhoff Portfolio vom Intel Atom® bis zum Intel® Xeon® deckt alle Leistungsstufen ab und ermöglicht eine echtzeitfähige, kosteneffiziente Integration der KI-Modelle in den TwinCAT-Laufzeitprozess.
GPU-beschleunigte Ausführung: Bei größeren neuronalen Netzen oder hohen Latenzanforderungen empfiehlt sich der Einsatz von GPU-basierten Systemen. Der Ultra-Kompakt-Industrie-PC C6043 mit Intel®-CoreTM-i und NVIDIA®-GPU (z. B. RTXTM A500 oder RTXTM 2000) bietet die nötige Rechenleistung, um komplexe Deep-Learning- oder Vision-Modelle in nahezu Echtzeit auszuführen, direkt aufgerufen aus dem SPS-Code.
Software
Für den produktiven Einsatz von KI-Modellen stehen zwei Architekturen zur Verfügung, die sich in Ausführungsart, Latenzverhalten und Hardwareeinsatz unterscheiden. Beide Varianten integrieren sich vollständig in die TwinCAT-Umgebung und unterstützen den offenen ONNX-Standard.
Inferenz in der TwinCAT-Laufzeit: Das KI-Modell wird direkt im Echtzeitkontext der Steuerung (XAR) ausgeführt. Die Berechnung erfolgt synchron und deterministisch auf der CPU – ideal für Anwendungen mit festen Zykluszeiten oder harten Echtzeitanforderungen. Diese Variante benötigt keine zusätzliche Hardware und nutzt das gewohnte Beckhoff IPC-Portfolio. Sie eignet sich besonders für relativ kompakte Deep Learning- oder klassische ML-Modelle, bei denen geringe Latenzen und präzises Timing entscheidend sind.
Inferenz-Server (GPU-beschleunigt): Alternativ kann die KI-Ausführung in einem separaten Server-Prozess erfolgen. Diese Architektur ermöglicht nahe Echtzeitverarbeitung bei gleichzeitig massiv höherer KI-Rechenleistung durch GPU-Unterstützung – insbesondere in Kombination mit dem C6043 Ultra-Kompakt-Industrie-PC mit integrierter NVIDIA®-RTXTM-GPU. Sie ist optimal für größere Deep-Learning-Modelle, bei denen hohe Modellkomplexität und kurze Reaktionszeiten zusammentreffen. Darüber hinaus erlaubt der Server-Ansatz Multi-Client-Verbindungen und somit eine zentrale Bereitstellung von KI-Modellen für mehrere Steuerungen.
Folgender Tabelle sind die jeweiligen Eigenschaften zu entnehmen:
| Ausführung | Eigenschaften | Typische Produkte |
|---|---|---|
| Inferenz in der TwinCAT-Laufzeit |
harte Echtzeit-Ausführung CPU-basiert hochoptimierte Modelle ONNX-kompatibel |
TF3800 | TwinCAT 3 Machine Learning Inference Engine TF3810 | TwinCAT 3 Neural Network Inference Engine TF7810 | TwinCAT 3 Vision Neural Network |
| Inferenz-Server (separater Prozess) |
nahe Echtzeit GPU-Unterstützung Multi-Client-Betrieb ONNX-kompatibel |
TF3820 | TwinCAT 3 Machine Learning Server TF3830 | TwinCAT 3 Machine Learning Server Client |
KI-Modelle besitzen die Eigenschaft, dass sie durch Training mit größeren Datenmengen besser werden. Ebenso können sich Rahmenbedingungen an der Maschine im Betrieb schleichend oder spontan ändern. Um dieser Eigenschaft Rechnung zu tragen, können Sie die KI-Modelle während der Laufzeit der Maschine updaten: ohne Maschinen-Stopp, ohne neues Kompilieren und vollständig remote über die Standard-IT-Infrastruktur. Egal für welches TwinCAT-Produkt zur Ausführung der KI-Modelle Sie sich entscheiden, es kann ein neues KI-Modell auf den Steuerungscomputer übertragen und über SPS-Funktionen neu geladen werden.
Darüber hinaus können Sie auch Ihre Trainingsumgebung remote oder lokal auf dem Industrie-PC im Betriebssystemkontext betreiben und damit nah am Prozess Modelle neu trainieren, austauschen und mit TwinCAT laden.
Anwendungsbeispiele für Künstliche Intelligenz in der Steuerung

In der diskreten Fertigung von metallischen Werkstücken ist oft die geometrische Form ein wesentliches Qualitätsmerkmal. Neben metrischen Messverfahren, um ein Werkstück quantitativ zu beurteilen, genügen oft auch qualitative Aussagen, wie beispielsweise die klassische Kategorisierung in OK und nicht-OK.
Es wurde ein repräsentativer Datensatz von ca. 200 Bildern mit Hilfe der TwinCAT-Vision-Bibliothek aufgenommen und abgespeichert. Die Daten wurden als OK und nicht-OK annotiert, wobei diverse unterschiedliche Fehlerbilder zusammen als nicht-OK zusammengefasst wurden. Mit TE3850 TwinCAT 3 Machine Learning Creator konnte auf diesem Datensatz basierend ein Bildklassifikationsmodell trainiert werden, welches in mehr als 95 % der betrachteten Fälle vorhersagen kann, ob ein Werkstück OK oder nicht-OK ist – und das ganz ohne KI-Expertenwissen.
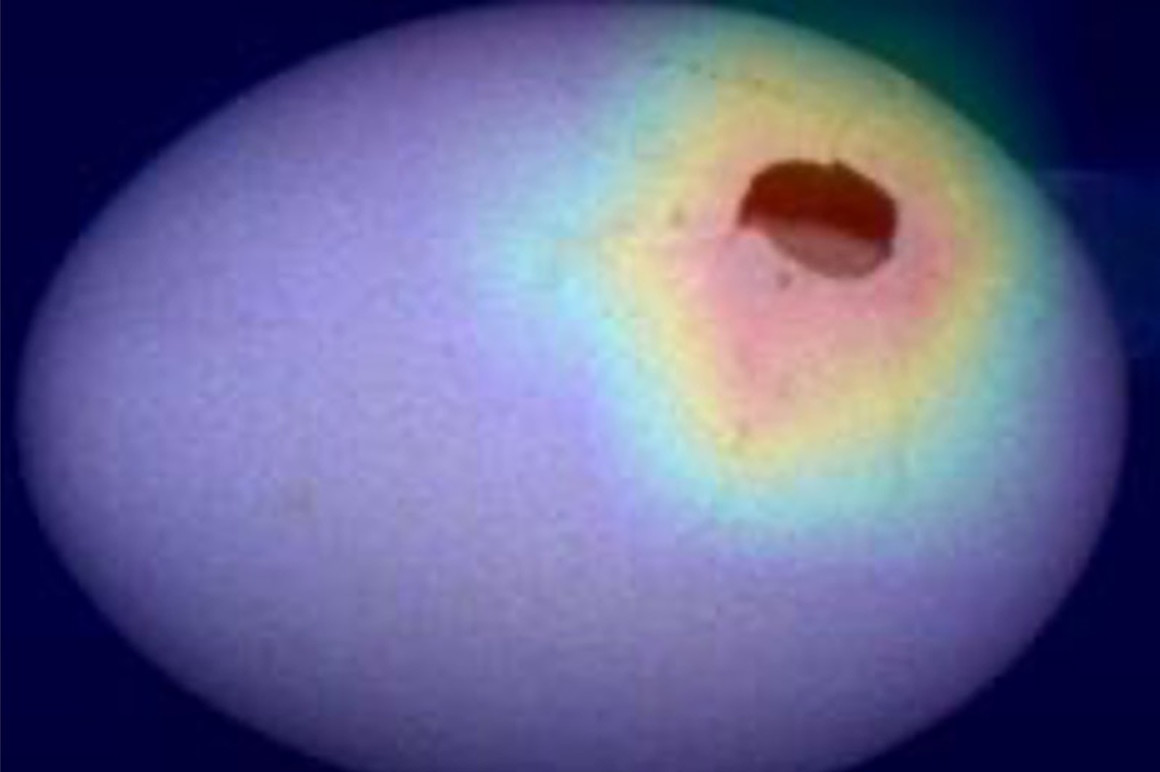
Die Automatisierung in der Lebensmittelindustrie trägt zur effizienten und ressourcenschonenden Versorgung mit unterschiedlichsten Lebensmitteln bei. Eine Herausforderung ist die automatisierte Sortierung von Lebensmitteln, da diese im Vergleich zu künstlich hergestellten Produkten eine hohe naturgegebene Varianz aufweisen. Im Kontext der Sortierung von Eiern soll in diesem Fall automatisch sortiert werden in die Kategorien OK, verschmutzt und zerbrochen. Dazu wurden 200 Bilder mit diesen drei Klassen aufgenommen und annotiert. Mit TE3850 TwinCAT 3 Machine Learning Creator konnte ein KI-Modell erstellt werden, welches in mehr als 90 % der betrachteten Fälle ein Ei korrekt klassifizieren kann. Mit den im Produkt enthaltenen Erklärbarkeits-Methoden für KI-Modelle konnte leicht herausgefunden werden, dass Fehlklassifikationen gerade in Randbereichen von OK zu verschmutzt auftraten. Dadurch wurde sofort ersichtlich, welche Maßnahmen zur Modellverbesserung eingeleitet werden müssen: Entweder mehr Beispieldaten im Randbereich zwischen OK und verschmutzt zur Verfügung stellen, oder die Grenze sauberer zu definieren durch Revision der vorhanden Annotationen.
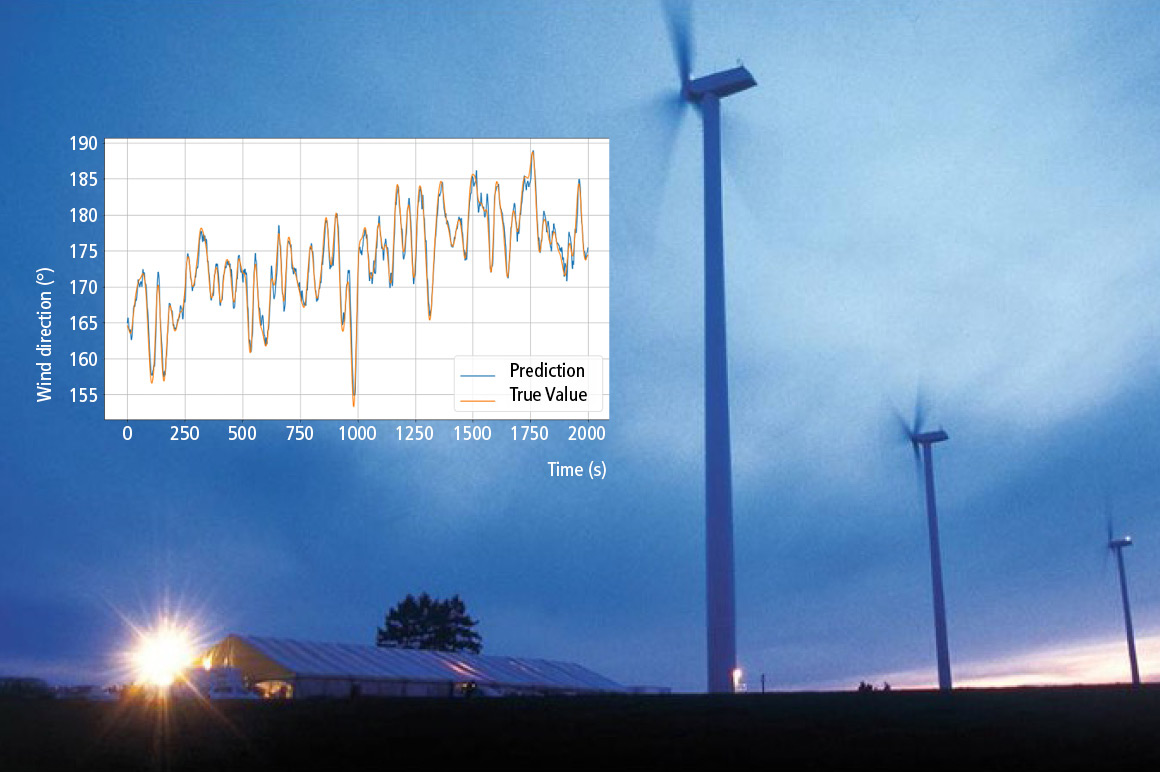
Windkraftanlagen sind ein wesentlicher Baustein in der Umstellung auf erneuerbare Energien. Sie liefern saubere, elektrische Energie, welche sie aus der Bewegungsenergie des Windes beziehen. Dabei ist es für den Wirkungsgrad der Anlage von entscheidender Bedeutung, sowohl die Windrichtung als auch die Windgeschwindigkeit zu kennen. Entsprechend der Windrichtung wird der an der Gondel befestigte Rotor zur Windrichtung ausgerichtet. Außerdem wird der Pitch der Rotorblätter entsprechend der Windgeschwindigkeit angepasst, sodass die Anlage möglichst konstant mit ihrer Nennleistung betrieben wird.
Die Windrichtungsnachführung und die Einstellung des Pitches erfolgt relativ langsam. Dadurch ergibt sich die Anforderung, dass die zukünftige Windrichtung und Windgeschwindigkeit geschätzt werden müssen, um die Anlage prädiktiv in die optimale Ausrichtung zu bewegen.
Auf Basis von gesammelten Wind-Daten aus realen Windkraftanlagen wurde ein KI-Modell erstellt, welches in der Lage ist, mit akzeptabler Fehlertoleranz Werte von Windrichtung und Windgeschwindigkeit, die 10 bis 20 Sekunden in der Zukunft liegen, zu schätzen. Und das nur auf Basis vergangener Windwerte. Das erstellte Modell lässt sich einfach mit TF3810 TwinCAT 3 Neural Network Inference Engine in TwinCAT integrieren.
Ein mechanischer Bolzenanker besteht im Wesentlichen aus dem Bolzen, einer U-Scheibe, einer Sechskantmutter sowie einer metallischen Hülse. Für ausreichende Haftung im Einsatz sorgen die Reibkräfte zwischen der Hülse und der Wandung des Bohrlochs. Um die für die Haltekraft notwendigen Normalkräfte auf das Bohrloch aufzubringen, wird die Hülse über einen konusförmigen Kopf des Metallbolzens mit der Bohrung verspreizt.
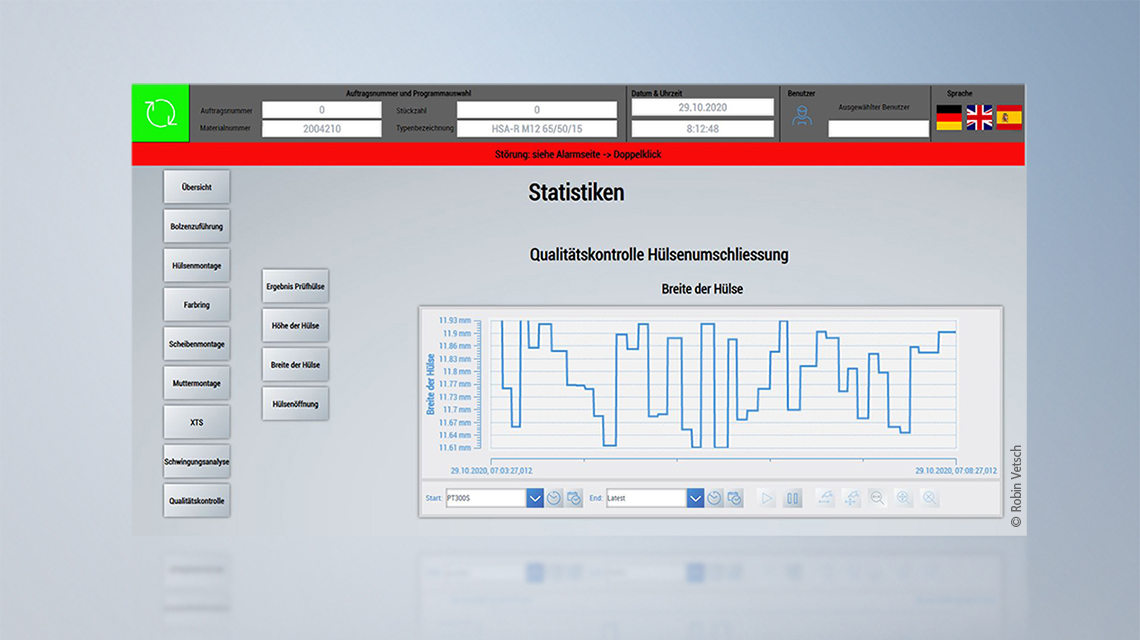
Das von R&D-Ingenieur Robin Vetsch im Rahmen des OST-Studiengangs Bachelor of Science Systemtechnik federführend bearbeitete Projekt fokussierte sich auf den Umschließungsprozess, wobei die vorgeformte, gestanzte Hülse den konischen Hals des Bolzenankers umschließt. Für die Qualitätskontrolle sollten lediglich die bereits vorhandenen Maschinendaten verwendet, also keine zusätzlichen Sensoren verbaut werden.
Bisher wurde die Umschließungsqualität der Hülse um den Bolzen mehrheitlich manuell mit einer Prüflehre durchgeführt. Nun wurde gezeigt, dass jede Umschließung in drei verschiedene Klassen (zu wenig umschlossen, in Ordnung, zu fest umschlossen) innerhalb der Qualitätsvorgaben eingeteilt werden kann. Auch sollen die geometrischen Eckdaten der umschlossenen Hülse (Hülsenbreite, -höhe und -öffnung) mit einer Regression vorhergesagt werden. Durch die 100-%-Kontrolle des Umschließungsvorgangs sollen Trends oder Abweichungen frühzeitig erkannt werden.

Instant-Nudeln sind in China in fast jedem Lebensmittelgeschäft zu finden. Um die Anzahl der Produkte mit Verpackungsfehlern und die damit verbundenen Kundenreklamationen zu reduzieren, entschied sich ein großer chinesischer Produzent von Instant-Nudeln für den Einsatz der Beckhoff Steuerungstechnik inklusive TwinCAT Machine Learning. Möglich wurde damit eine intelligente und zuverlässige Echtzeitinspektion der Verpackungsqualität.
Zunächst wurden die Sensordaten über EtherCAT-Digital- und -Analog-Eingangsklemmen EL1xxx bzw. EL3xxx und TE1300 TwinCAT 3 Scope View Professional erfasst. Anschließend wurde das KI-Modell über das Open-Source-Framework Scikit-learn trainiert und daraus die Modellbeschreibungsdatei erzeugt. Die notwendige Vorverarbeitung der Sensordaten wurde mithilfe von TF3600 TwinCAT 3 Condition Monitoring in der Steuerung realisiert. Dann erfolgte das Deployment der Modellbeschreibungsdatei auf einen Embedded-PC CX51x0, der das KI-Modell mithilfe von TF3800 TwinCAT 3 Machine Learning Inference Engine in Echtzeit ausführt und die Inferenzergebnisse zur Erkennung fehlerhafter Produkte über eine EtherCAT-Digital-Ausgangsklemme EL2xxx ausgibt. Dabei kam insbesondere die Systemoffenheit als großer Vorteil der Steuerungstechnik von Beckhoff zum Tragen. Denn diese konnte ohne großen Aufwand nahtlos in die bestehende Drittanbieter-Hauptsteuerung der Produktionslinie integriert werden.
Produkte

TE3850 | TwinCAT 3 Machine Learning Creator
Der TwinCAT 3 Machine Learning Creator erstellt auf Basis von Datensätzen automatisiert KI-Modelle. Diese KI-Modelle lassen sich hinsichtlich der Genauigkeit und Latenz optimieren und sind so optimal auf die Ausführung auf Beckhoff Industrie-PCs mit TwinCAT-Produkten abgestimmt. Die generierten Modelle können auch als standardisierte ONNX-Modelle außerhalb der Beckhoff Produkte eingesetzt werden. Für die Ausführung des KI-Modells mit TwinCAT-Produkten wird neben dem Modell zusätzlich eine PLCopen XML-Datei mit IEC 61131-3-Code erstellt, welche die komplette KI-Pipeline beschreibt und nahtlos in TwinCAT importiert werden kann.

TE3851 | TwinCAT 3 Machine Learning Creator Computer Vision
Bei TE3851 TwinCAT 3 MLC Computer Vision handelt es sich um ein Erweiterungspaket für die Basis-Webapplikation TE3850 TwinCAT 3 Machine Learning Creator. Mit dieser Erweiterung wird das Erstellen von KI-Modellen für den Bereich Bildverarbeitung, z. B. Bildklassifikation, ermöglicht.

TE3852 | TwinCAT 3 Machine Learning Creator Signals and Time Series
Bei TE3852 TwinCAT 3 MLC Signals and Time Series handelt es sich um ein Erweiterungspaket für die Basis-Webapplikation TE3850 TwinCAT 3 Machine Learning Creator. Mit dieser Erweiterung wird das Erstellen von KI-Modellen für den Bereich Signale und Zeitreihen, z. B. Klassifikation, Anomaliedetektion und Forecasting, ermöglicht.
TE3860 | TwinCAT 3 Machine Learning Creator Resource Pack
Bei TE3860 TwinCAT 3 MLC Resource Pack handelt es sich um ein Erweiterungspaket für die Basis-Webapplikation TE3850 TwinCAT 3 Machine Learning Creator. Sollte mehr Computing Time benötigt werden, etwa zum Training weiterer KI-Modelle, kann zusätzliche Computing Time flexibel über dieses Erweiterungspaket bezogen werden.

TF3800 | TwinCAT 3 Machine Learning Inference Engine
Die TwinCAT 3 Function TF3800 ist ein hochperformantes Ausführungsmodul (Inferenzmaschine) für trainierte, klassische, maschinelle Lernalgorithmen.

TF3810 | TwinCAT 3 Neural Network Inference Engine
Die TwinCAT 3 Function TF3810 ist ein hochperformantes Ausführungsmodul (Inferenzmaschine) für trainierte, neuronale Netze.

TF3820 | TwinCAT 3 Machine Learning Server
TF3820 TwinCAT 3 Machine Learning Server ist ein hochperformanter Dienst zur Ausführung trainierter KI-Modelle mit der Option, Hardwarebeschleuniger zu nutzen.
TF3830 | TwinCAT 3 Machine Learning Server Client
Der TwinCAT 3 Machine Learning Server beinhaltet standardmäßig eine Verbindung zu einem lokalen Client (lokale TwinCAT-Laufzeit). Sollen (ggf. weitere) TwinCAT-Laufzeiten remote auf einen TwinCAT 3 Machine Learning Server zugreifen, müssen diese Laufzeiten jeweils mit einer Lizenz für den TF3830 TwinCAT 3 Machine Learning Client ausgestattet werden.

TF7800 | TwinCAT 3 Vision Machine Learning
TwinCAT 3 Vision Machine Learning bietet eine integrierte Lösung für Maschinelles Lernen (ML) für Vision-spezifische Anwendungsfälle. Sowohl das Training als auch die Ausführung der Machine-Learning-Modelle erfolgen in der Echtzeit. Mithilfe dieser Modelle können komplexe Datenanalysen automatisch gelernt werden. Damit lassen sich aufwendige, manuell erstellte Programmkonstrukte ersetzen.
TF7810 | TwinCAT 3 Vision Neural Network
TwinCAT 3 Vision Neural Network bietet eine integrierte Lösung für Maschinelles Lernen (ML) für Vision-spezifische Anwendungsfälle. Die Ausführung der Machine-Learning-Modelle erfolgt in der Echtzeit. Mithilfe dieser Modelle können komplexe Datenanalysen automatisch gelernt werden. Damit lassen sich aufwendige, manuell erstellte Programmkonstrukte ersetzen.

C6043 | Ultra-Kompakt-Industrie-PC mit NVIDIA® GPU
Der Industrie-PC C6043 mit NVIDIA®-GPU ermöglicht Anwendungen mit hohen Ansprüchen an 3D-Grafik oder tief integrierte Vision- und KI-Programmbausteine bei minimalen Zykluszeiten. Er erweitert die Baureihe ultra-kompakter Industrie-PCs um ein performantes Gerät mit einem ab Werk belegbaren Slot für leistungsstarke Grafikkarten. Durch die modernsten Intel® Core™ Prozessoren und hoch-parallelisierende NVIDIA®-Grafikprozessoren lässt sich der PC perfekt als zentrale Steuerungseinheit für sehr komplexe Applikationen nutzen. Die Beckhoff Steuerungssoftware TwinCAT 3 kann dies vollintegriert abbilden – ohne weitere Software oder Schnittstellen. Mit dem zusätzlich frei belegbaren PCIe®-Kompakt-Modulslot kann der C6043 flexibel um ergänzende Funktionen erweitert werden.

C6675 | Schaltschrank-Industrie-PC
Der Industrie-PC C6675 ist mit Komponenten der höchsten Leistungsklasse ausgestattet: Auf einem ATX-Motherboard kommen wahlweise der Intel® Processor 300 oder die Prozessoren Intel® Core™ 3/5/7/9 Series 2 zum Einsatz. Das übernommene Gehäuse- und Kühlkonzept vom C6670 ermöglicht darüber hinaus u. a. den Einsatz einer GPU-Accelerator-Karte. Für Steckkarten voller Baulänge stehen in Summe 300 Watt zur Verfügung. Applikationen im Bereich des maschinellen Lernens oder Vision können so im industriellen Umfeld realisiert werden.